
















.avif)








.avif)











When Sung Jo joined Clay's growth team as SEO/AEO Lead, he was given a thought experiment: imagine you have unlimited budget, unlimited resources, and no legacy constraints. How would you run your SEO/AEO program?
The question wasn't hypothetical for the sake of it. SEO and AEO have evolved fast enough that the right answer today looks nothing like the right answer two years ago. People discover tools through Google, but they also discover them by asking ChatGPT or Claude for a recommendation. They read blog posts, but they also skim LLM-generated summaries that may or may not mention your product. The surface area for discoverability has expanded, and the systems that serve it need to expand with it.
Sung spent his first 30 days thinking about that surface area from first principles. Not what content to produce next, but what systems would make Clay consistently discoverable across search engines and AI models, and what would make that experience genuinely useful for the person on the other end. Someone trying to understand what Clay does, or learning how to become a GTM Engineer, or asking an LLM which data enrichment tools exist for their specific use case. The goal was to meet all of those people with accurate, current, helpful information, wherever they're looking.
What he built was three systems, each solving a different part of that problem. This post walks through all three: what they do, how they work inside Clay, and why the approach reflects a broader shift from content production toward content engineering. There are also templates for each to help get you started in Clay.
TL;DR
- Clay's SEO/AEO Lead built three Clay-powered systems to handle content refresh, video-to-page conversion, and LLM visibility tracking at scale.
- A Clay table automates continuous refresh of 8,000+ dossier pages by pulling from Webflow, checking for data changes, rewriting stale sections, and pushing updates back to the CMS.
- Claygent converts video transcripts into structured, searchable tutorial pages, turning low-visibility Loom recordings into indexed, linkable content.
- A custom AI visibility dashboard built in two days tracks brand mentions, sentiment, and competitor share of voice across LLM responses, at a fraction of the cost of off-the-shelf AEO tools.

Why the traditional SEO pipeline breaks down
The standard SEO content workflow runs roughly like this: keyword research takes a day, writing a brief takes two days, handoff and alignment takes another day, writing and editing takes a week, and feedback and publishing takes a few more days. About two weeks per article, one article per week.

That pipeline was designed for a world where discoverability meant ranking on Google. It assumed a manageable volume of pages, a stable set of ranking factors, and content that stayed relevant for months after publishing. None of those assumptions hold anymore.

What Sung built instead treats content the way a GTM engineer treats a data workflow: structured inputs, systematic processing, human judgment at the decision points, and throughput that scales with the system rather than the headcount. Under this model, the timeline compresses from two weeks to about three days, and the output isn't one article. It's as many as the system can process in that window.
Clay Play 1: Refreshing existing content at scale
The first problem Sung tackled was stale content.
Clay maintains a large library of "dossier" pages: detailed profiles of companies and executives that answer questions people are actively searching. These pages perform well when they're accurate and become liabilities when they're not. A page titled "Who is the CTO of Shopify in 2026?" that still shows a previous executive will fail to rank, will actively erode trust with anyone who lands on it, and it gives LLMs bad information to cite.

The manual approach to this problem is familiar to anyone who's worked in content operations. You audit the library, flag what's stale, assign someone to update each page, QA the updates, and publish. Then you do it again in six months when everything is stale again.
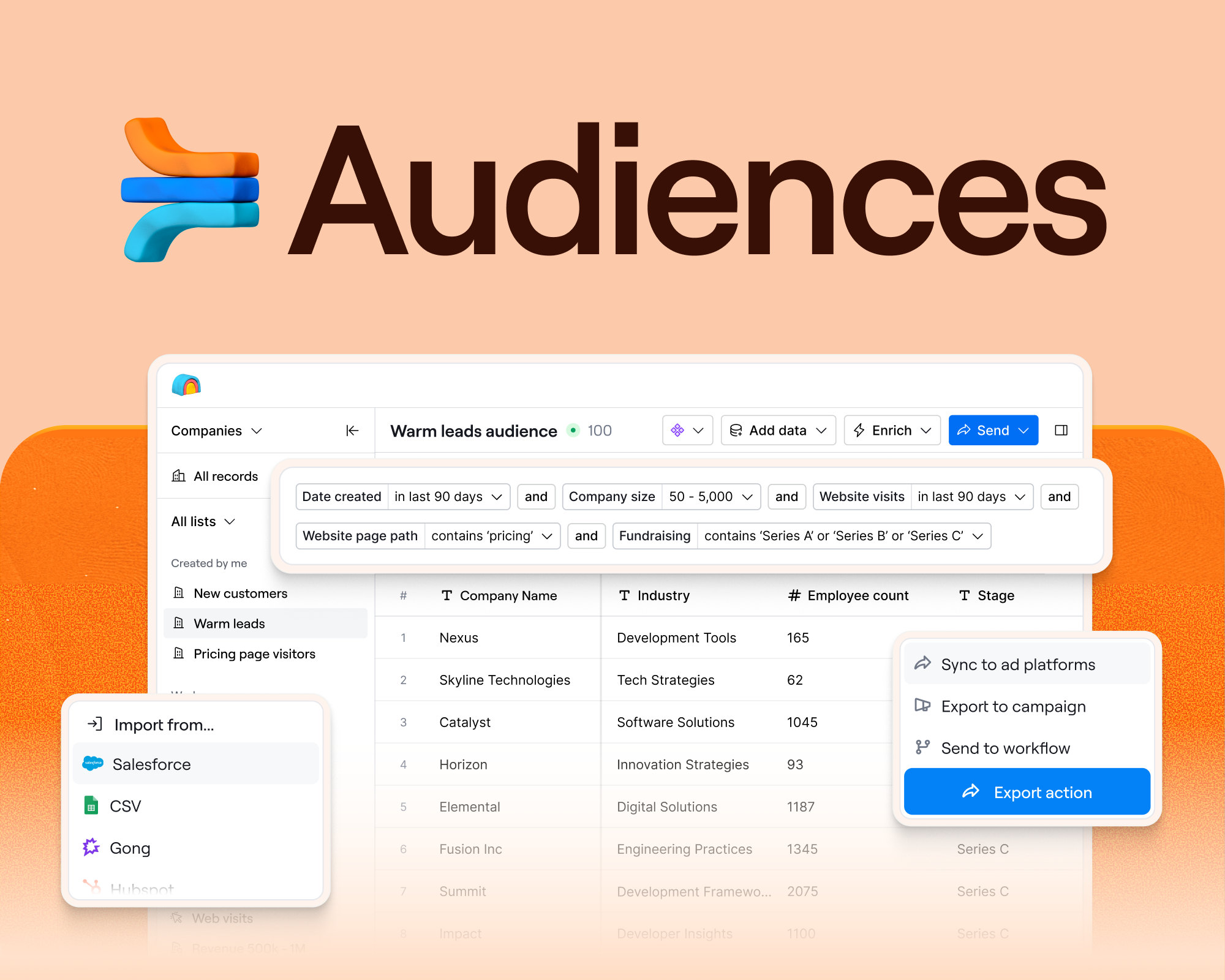
But with a library of over 8,000 pages all needing maintenance, content refresh could quickly become his full-time job. Instead, Sung built a Clay table that automates the loop.
The table pulls down existing page content from Webflow, runs enrichment to check whether the underlying data has changed (new executives, updated company information, shifted org structures), flags pages where the content no longer matches reality, uses LLMs to rewrite the stale sections with current data, and pushes the updated content back into the CMS.
Because the whole thing runs through Clay's Webflow integration, it operates on a continuous cycle. Pages don't sit stale for months waiting for someone to notice. Fresh content is automatically updated in the CMS.
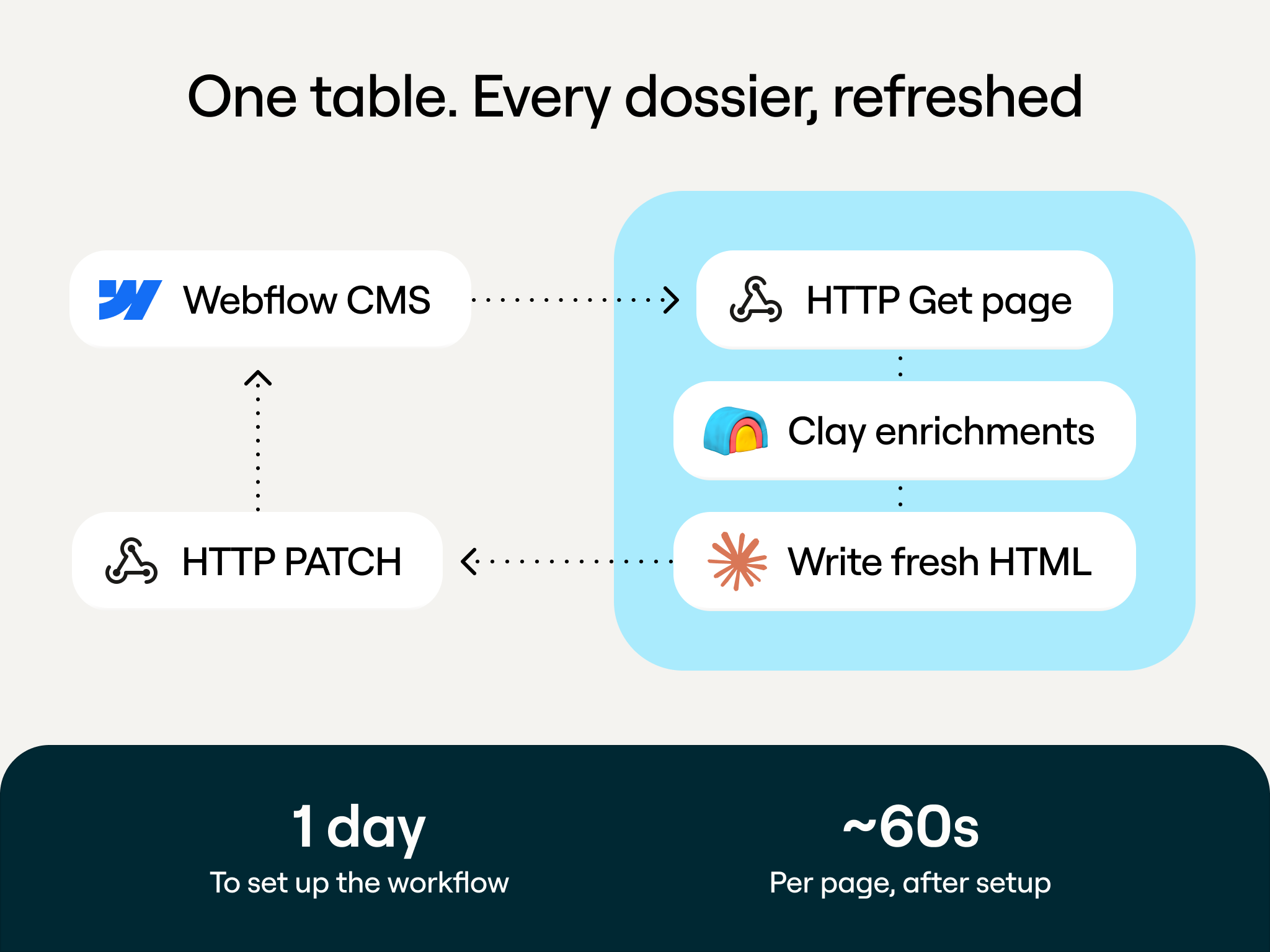
The before and after is visible. A dossier page that previously showed Troy Stevenson as Uber's COO now correctly shows Andrew Macdonald, with updated work history, education, and tenure details. That's one page. The system handles the other 8,000 pages the same way, automatically.

Want to try this yourself in Clay? Here's the Dossier Refresh Start template to get started.
Clay Play 2: Turning video content into searchable pages
Clay produces a lot of video content: webinars, Loom walkthroughs, product demos. That content is often the most detailed and practical material the company has. It's also effectively invisible to both search engines and LLMs. Video transcripts aren't indexed the same way written content is, and nobody is going to watch a seven-minute Loom to find the answer to a specific question.
The second system Sung built converts video content into structured, searchable tutorial pages.
The workflow starts with a transcript. That transcript goes into a Clay table, where Claygent analyzes the content and extracts the logical steps: what tools were used, what the workflow does, how to get started, and what the expected output looks like. The result is a complete template page with a description, a list of Clay features used, a step-by-step guide, and an embedded video for anyone who wants the full walkthrough.
One example: a Loom recording walking through how to craft outbound email campaigns with case studies became a full Clay University template page. The original video had 141 views on Loom. The template page is now discoverable through search, linkable, and structured in a way that LLMs can reference when someone asks how to personalize outbound emails.
Every webinar Clay has ever recorded is a potential source of multiple template pages. The constraint isn't production capacity. It's deciding which videos to prioritize.
Build this yourself in Clay by creating a table using the Claybook Creator template.
Clay Play 3: Building an AI visibility dashboard from scratch
The third system is the most technically ambitious, and it illustrates a principle worth spending time on.
When Sung started evaluating AEO monitoring tools, he found a growing market of products that track how brands show up in LLM responses. They work by sending prompts to various models, parsing the responses, and reporting on mentions, sentiment, and competitive positioning.
After evaluating several, he realized two things. First, every one of these tools is calling the same LLM APIs that already live inside Clay. The differentiation is in the parsing and presentation, not the data retrieval. Second, the parsing is exactly the part that needed to be customized. Off-the-shelf tools couldn't track how Clay's MCP app was being discussed, or how Claygent was being mentioned, or what the community sentiment was around a recent pricing change. These were the questions the growth team actually needed answered, and no vendor was going to ship those features on Clay's timeline.
So Sung built the whole thing in two days.
The system works in four stages:
- A list of prompts gets generated and classified by topic, intent, and use case. These map to categories defined with the PMM team, so the data is structured around the questions the business actually needs answered.
- Those prompts get sent to multiple LLMs through Clay, and the responses are parsed to extract brand mentions, competitor mentions, sentiment, citation sources, and positioning.
- The enriched data gets pushed to Supabase, which takes a daily snapshot and serves as the storage layer.
- Claude Code queries Supabase and generates a functional dashboard deployed on Vercel.
The dashboard tracks visibility score, citation rate, average position, sentiment breakdown, competitor share of voice, and prompt-level detail. It supports filtering by date range, platform, keyword type, and tags.
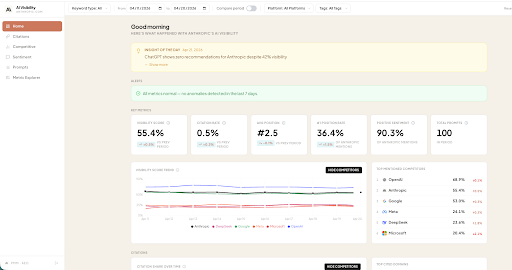
The proof of concept cost roughly five times less than the tools Sung had evaluated. But the real advantage is maintenance cost. The dashboard doesn't touch Clay's core data infrastructure or orchestration layer. It sits on top. If a better approach emerges in three months, the team can rebuild it in another two days. There's no migration, no contract to unwind, no sunk implementation to protect. The underlying systems (Clay for enrichment, Supabase for storage) stay the same. Only the analysis layer changes.
Here's the SEO/AEO Visibility template you can use in Clay to build your own.
What this adds up to
Stale content, underutilized video assets, and opaque LLM visibility are three distinct problems. But Sung approached all three the same way: identify the repeatable structure, build the system that handles it, and keep human judgment focused on the decisions that actually require it.
This is content engineering as a natural extension of GTM engineering. The same principles that let Clay's growth team run personalized outreach across hundreds of accounts also apply to making Clay discoverable across search and AI. The tools are the same. The logic is the same. The leverage is the same.
Want to see how these systems work from the inside? Watch Sung walk through the builds live in How Clay Uses Clay Episode 7 workshop, where he covers the end-to-end flow from prompt research to dashboard deployment.
Frequently Asked Questions
What is AEO and how is it different from SEO?
SEO focuses on ranking in traditional search engines like Google. AEO (Answer Engine Optimization) focuses on making your content discoverable and citable by AI models like ChatGPT and Claude. Both matter because people now discover tools through both channels, and the content structures that serve each are increasingly different.
How does Clay automate content refresh for thousands of pages?
Clay uses a Clay table connected to Webflow. The table pulls existing page content, runs enrichment to check whether underlying data has changed, flags stale sections, uses LLMs to rewrite them with current data, and pushes the updates back to the CMS automatically. The cycle runs continuously, so pages don't sit outdated for months.
How does Clay turn video content into searchable pages?
The workflow starts with a video transcript loaded into a Clay table. Claygent analyzes the transcript and extracts the logical steps, tools used, workflow description, and expected output. The result is a structured template page with a step-by-step guide and embedded video, indexed by search engines and referenceable by LLMs.
Can I build my own AI visibility dashboard without buying a dedicated AEO tool?
Yes. Sung built Clay's internal AEO dashboard in two days using Clay to send prompts to LLMs and parse responses, Supabase for storage, and Claude Code to generate a Vercel-deployed dashboard. The build cost roughly five times less than the off-the-shelf tools he evaluated, and the analysis layer can be rebuilt quickly if requirements change.
When Sung Jo joined Clay's growth team as SEO/AEO Lead, he was given a thought experiment: imagine you have unlimited budget, unlimited resources, and no legacy constraints. How would you run your SEO/AEO program?
The question wasn't hypothetical for the sake of it. SEO and AEO have evolved fast enough that the right answer today looks nothing like the right answer two years ago. People discover tools through Google, but they also discover them by asking ChatGPT or Claude for a recommendation. They read blog posts, but they also skim LLM-generated summaries that may or may not mention your product. The surface area for discoverability has expanded, and the systems that serve it need to expand with it.
Sung spent his first 30 days thinking about that surface area from first principles. Not what content to produce next, but what systems would make Clay consistently discoverable across search engines and AI models, and what would make that experience genuinely useful for the person on the other end. Someone trying to understand what Clay does, or learning how to become a GTM Engineer, or asking an LLM which data enrichment tools exist for their specific use case. The goal was to meet all of those people with accurate, current, helpful information, wherever they're looking.
What he built was three systems, each solving a different part of that problem. This post walks through all three: what they do, how they work inside Clay, and why the approach reflects a broader shift from content production toward content engineering. There are also templates for each to help get you started in Clay.
TL;DR
- Clay's SEO/AEO Lead built three Clay-powered systems to handle content refresh, video-to-page conversion, and LLM visibility tracking at scale.
- A Clay table automates continuous refresh of 8,000+ dossier pages by pulling from Webflow, checking for data changes, rewriting stale sections, and pushing updates back to the CMS.
- Claygent converts video transcripts into structured, searchable tutorial pages, turning low-visibility Loom recordings into indexed, linkable content.
- A custom AI visibility dashboard built in two days tracks brand mentions, sentiment, and competitor share of voice across LLM responses, at a fraction of the cost of off-the-shelf AEO tools.
Why the traditional SEO pipeline breaks down
The standard SEO content workflow runs roughly like this: keyword research takes a day, writing a brief takes two days, handoff and alignment takes another day, writing and editing takes a week, and feedback and publishing takes a few more days. About two weeks per article, one article per week.
That pipeline was designed for a world where discoverability meant ranking on Google. It assumed a manageable volume of pages, a stable set of ranking factors, and content that stayed relevant for months after publishing. None of those assumptions hold anymore.
What Sung built instead treats content the way a GTM engineer treats a data workflow: structured inputs, systematic processing, human judgment at the decision points, and throughput that scales with the system rather than the headcount. Under this model, the timeline compresses from two weeks to about three days, and the output isn't one article. It's as many as the system can process in that window.
Clay Play 1: Refreshing existing content at scale
The first problem Sung tackled was stale content.
Clay maintains a large library of "dossier" pages: detailed profiles of companies and executives that answer questions people are actively searching. These pages perform well when they're accurate and become liabilities when they're not. A page titled "Who is the CTO of Shopify in 2026?" that still shows a previous executive will fail to rank, will actively erode trust with anyone who lands on it, and it gives LLMs bad information to cite.
The manual approach to this problem is familiar to anyone who's worked in content operations. You audit the library, flag what's stale, assign someone to update each page, QA the updates, and publish. Then you do it again in six months when everything is stale again.
But with a library of over 8,000 pages all needing maintenance, content refresh could quickly become his full-time job. Instead, Sung built a Clay table that automates the loop.
The table pulls down existing page content from Webflow, runs enrichment to check whether the underlying data has changed (new executives, updated company information, shifted org structures), flags pages where the content no longer matches reality, uses LLMs to rewrite the stale sections with current data, and pushes the updated content back into the CMS.
Because the whole thing runs through Clay's Webflow integration, it operates on a continuous cycle. Pages don't sit stale for months waiting for someone to notice. Fresh content is automatically updated in the CMS.
The before and after is visible. A dossier page that previously showed Troy Stevenson as Uber's COO now correctly shows Andrew Macdonald, with updated work history, education, and tenure details. That's one page. The system handles the other 8,000 pages the same way, automatically.
Want to try this yourself in Clay? Here's the Dossier Refresh Start template to get started.
Clay Play 2: Turning video content into searchable pages
Clay produces a lot of video content: webinars, Loom walkthroughs, product demos. That content is often the most detailed and practical material the company has. It's also effectively invisible to both search engines and LLMs. Video transcripts aren't indexed the same way written content is, and nobody is going to watch a seven-minute Loom to find the answer to a specific question.
The second system Sung built converts video content into structured, searchable tutorial pages.
The workflow starts with a transcript. That transcript goes into a Clay table, where Claygent analyzes the content and extracts the logical steps: what tools were used, what the workflow does, how to get started, and what the expected output looks like. The result is a complete template page with a description, a list of Clay features used, a step-by-step guide, and an embedded video for anyone who wants the full walkthrough.
One example: a Loom recording walking through how to craft outbound email campaigns with case studies became a full Clay University template page. The original video had 141 views on Loom. The template page is now discoverable through search, linkable, and structured in a way that LLMs can reference when someone asks how to personalize outbound emails.
Every webinar Clay has ever recorded is a potential source of multiple template pages. The constraint isn't production capacity. It's deciding which videos to prioritize.
Build this yourself in Clay by creating a table using the Claybook Creator template.
Clay Play 3: Building an AI visibility dashboard from scratch
The third system is the most technically ambitious, and it illustrates a principle worth spending time on.
When Sung started evaluating AEO monitoring tools, he found a growing market of products that track how brands show up in LLM responses. They work by sending prompts to various models, parsing the responses, and reporting on mentions, sentiment, and competitive positioning.
After evaluating several, he realized two things. First, every one of these tools is calling the same LLM APIs that already live inside Clay. The differentiation is in the parsing and presentation, not the data retrieval. Second, the parsing is exactly the part that needed to be customized. Off-the-shelf tools couldn't track how Clay's MCP app was being discussed, or how Claygent was being mentioned, or what the community sentiment was around a recent pricing change. These were the questions the growth team actually needed answered, and no vendor was going to ship those features on Clay's timeline.
So Sung built the whole thing in two days.
The system works in four stages:
- A list of prompts gets generated and classified by topic, intent, and use case. These map to categories defined with the PMM team, so the data is structured around the questions the business actually needs answered.
- Those prompts get sent to multiple LLMs through Clay, and the responses are parsed to extract brand mentions, competitor mentions, sentiment, citation sources, and positioning.
- The enriched data gets pushed to Supabase, which takes a daily snapshot and serves as the storage layer.
- Claude Code queries Supabase and generates a functional dashboard deployed on Vercel.
The dashboard tracks visibility score, citation rate, average position, sentiment breakdown, competitor share of voice, and prompt-level detail. It supports filtering by date range, platform, keyword type, and tags.
The proof of concept cost roughly five times less than the tools Sung had evaluated. But the real advantage is maintenance cost. The dashboard doesn't touch Clay's core data infrastructure or orchestration layer. It sits on top. If a better approach emerges in three months, the team can rebuild it in another two days. There's no migration, no contract to unwind, no sunk implementation to protect. The underlying systems (Clay for enrichment, Supabase for storage) stay the same. Only the analysis layer changes.
Here's the SEO/AEO Visibility template you can use in Clay to build your own.
What this adds up to
Stale content, underutilized video assets, and opaque LLM visibility are three distinct problems. But Sung approached all three the same way: identify the repeatable structure, build the system that handles it, and keep human judgment focused on the decisions that actually require it.
This is content engineering as a natural extension of GTM engineering. The same principles that let Clay's growth team run personalized outreach across hundreds of accounts also apply to making Clay discoverable across search and AI. The tools are the same. The logic is the same. The leverage is the same.
Want to see how these systems work from the inside? Watch Sung walk through the builds live in How Clay Uses Clay Episode 7 workshop, where he covers the end-to-end flow from prompt research to dashboard deployment.
Frequently Asked Questions
What is AEO and how is it different from SEO?
SEO focuses on ranking in traditional search engines like Google. AEO (Answer Engine Optimization) focuses on making your content discoverable and citable by AI models like ChatGPT and Claude. Both matter because people now discover tools through both channels, and the content structures that serve each are increasingly different.
How does Clay automate content refresh for thousands of pages?
Clay uses a Clay table connected to Webflow. The table pulls existing page content, runs enrichment to check whether underlying data has changed, flags stale sections, uses LLMs to rewrite them with current data, and pushes the updates back to the CMS automatically. The cycle runs continuously, so pages don't sit outdated for months.
How does Clay turn video content into searchable pages?
The workflow starts with a video transcript loaded into a Clay table. Claygent analyzes the transcript and extracts the logical steps, tools used, workflow description, and expected output. The result is a structured template page with a step-by-step guide and embedded video, indexed by search engines and referenceable by LLMs.
Can I build my own AI visibility dashboard without buying a dedicated AEO tool?
Yes. Sung built Clay's internal AEO dashboard in two days using Clay to send prompts to LLMs and parse responses, Supabase for storage, and Claude Code to generate a Vercel-deployed dashboard. The build cost roughly five times less than the off-the-shelf tools he evaluated, and the analysis layer can be rebuilt quickly if requirements change.
.png)








.avif)



























.avif)





















.avif)




























.avif)




